Modern AI relies heavily on deep learning, which begins with data. Data, in terms of quantity and quality, is key to the final model quality. Along with computational power, it has driven most of the AI improvements in recent years.
Deep learning teams therefore face a mountain of data on a daily basis. It's not just about storing it. It's about refining it, exploring it, and getting it ready for training powerful models efficiently. When working with image models, visualization and exploration of the data is key. We've been wrestling with this challenge and want to share our solution: Dataroom, a data and image storage, curation, and access platform we're releasing as open source today: github.com/photoroom/dataroom
The "Data Refinery"
We think of data as something that's rarely static. It goes through cycles of filtering, augmentation, and improvement. We call this model the "Data Refinery".
It starts with raw data (bronze), collected from various sources, often with no quality guarantees. This raw data then needs to be collected and structured. The structured data (silver) then needs to be validated, augmented, and enriched. Finally, we get to validated & enriched data and ML datasets (gold). This data has been annotated, curated (sometimes by humans, sometimes by sophisticated ML models). We can then use this data to train models and evaluate their performance, which often leads back to further curation of the data. We subscribe to the “Data Refinery” mental model: Data is rarely completely at rest and will go through several cycles of filtering and augmentation. Illustration from Roman Frigg
We subscribe to the “Data Refinery” mental model: Data is rarely completely at rest and will go through several cycles of filtering and augmentation. Illustration from Roman Frigg
The curation loop at the top of the pyramid, where golden datasets are further improved to fit the data distribution required for training a given model, is very important. Iterating on the "curate data → train new model → evaluate → curate better data → train better model" loop needs to be fast and efficient. Having simple, quick access to data and making it interactively explorable, queryable, shareable, and extendable is key to reduce iteration times. It helps to drastically increase research output.
Hurdles with traditional setups
For a while, like many others, we relied on formats like Parquet or Webdataset to do dataset curation. These are great for training at scale, offering excellent throughput and solid tooling support. You can get started with training on multimodal data right away.
But in some cases these formats slowed us down, especially when dealing with the iterative nature of data work:
"Slice and dice" is slow: Exploring specific subsets of data or trying out new filtering ideas wasn't interactive. It was costly and time-consuming.
Processing rigidity: When you process data, it often mutates whole shards. This makes it hard to mix and match different processing steps later on or easily recover if you realize a filtering step was wrong. Traditional approaches often assume a linear data lineage, but the reality is often more complex.
Limited view & iteration unfriendliness: These formats aren't always the friendliest when you need to quickly iterate on your dataset based on new insights, when combined to several processing steps. They miss the atomicity and quick per-sample flagging which make it easy to start small, close the loop, iterate then scale things up.
 Example data preparation flow: All good, until you have to iterate because one of these steps was perfectible. Linear lineage and complete processing before moving to next steps are implicitly assumed.These issues become even more pronounced with Generative AI, which has stringent needs around what content should (and shouldn't) be in your dataset. When you're dealing with potentially 100 million samples or more, you need a more flexible approach.
Example data preparation flow: All good, until you have to iterate because one of these steps was perfectible. Linear lineage and complete processing before moving to next steps are implicitly assumed.These issues become even more pronounced with Generative AI, which has stringent needs around what content should (and shouldn't) be in your dataset. When you're dealing with potentially 100 million samples or more, you need a more flexible approach.
Vector databases
We started looking for a better way and landed on vector databases. A vector DB allow to search multi modal data, based on proximity metrics (like finding similar images or text) on top of standard attribute-based querying.
Here's why this clicked for us:
Great for attributes and exploration: Databases are mature and excellent for slicing and dicing data based on attributes and different dimensions efficiently. Being able to combine attribute-based querying with semantic search on vector embeddings (hybrid search) is a game changer for us. We can search for “images containing a panda, ingested after January 2024, not in dataset ‘evals’ and from source ImageNet” and get results within milliseconds from a database with more than 100 million records.
Powerful for understanding distributions: Vector embeddings are fantastic for monitoring and controllably changing your overall data distribution. Being able to explore the embedding space visually and programmatically, makes it possible to easily identify gaps in the data.
Scalable and fast for interactive use: Vector DBs can be scaled by sharding them across multiple hosts and parallelizing requests. Modern vector query paths are highly optimized, allowing nearest neighbor searches over huge datasets in milliseconds.
Introducing Dataroom
This led us to build Dataroom. It's a platform designed around the “train → eval → curate” loop at the top of the data refinery pyramid we described above. It’s backed by Elastic Search (we use OpenSearch hosted on AWS), which provides the powerful vector and attribute search. We also created a fast client we call datago, written in Rust to be able to query and download data from Dataroom blazingly fast.
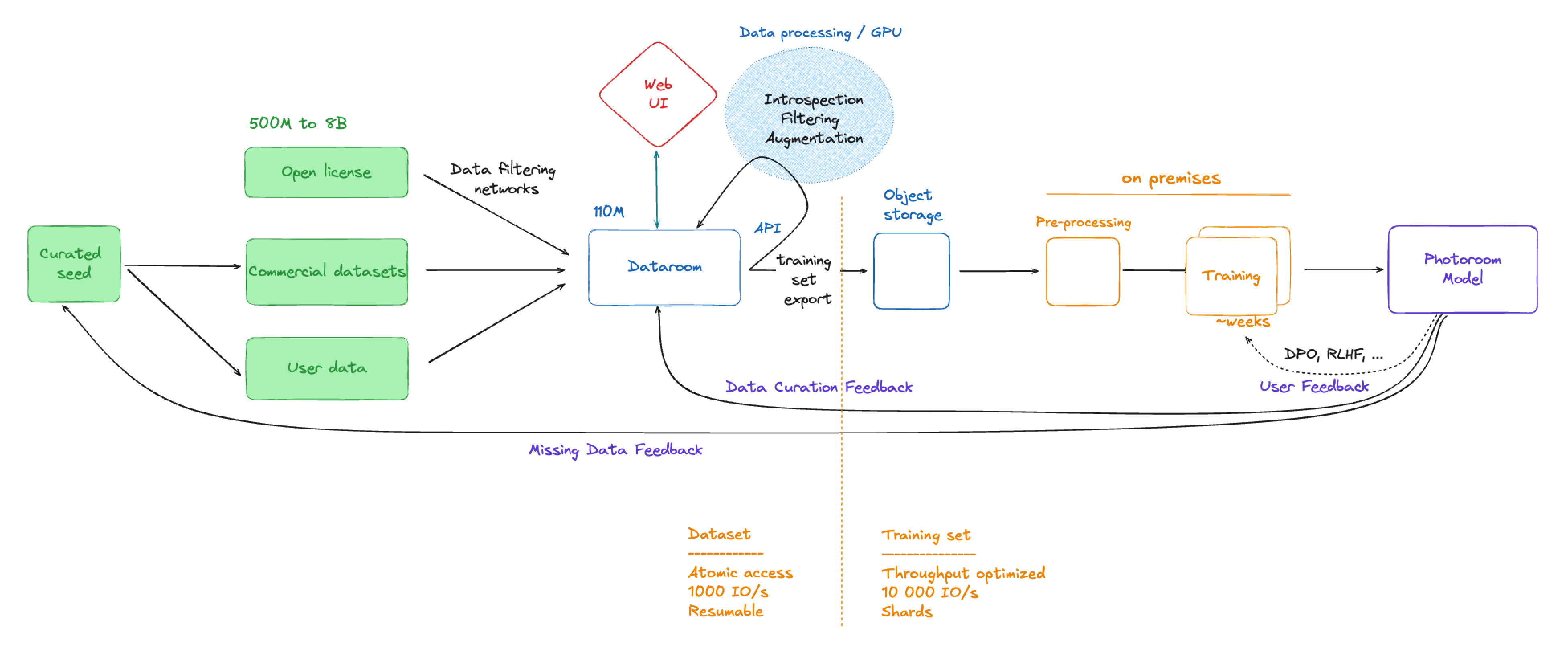 Dataroom sits at the heart of the deep learning lifecyle at Photoroom. From data ingestion, dataset curation then handling user feedback, to even making it possible to track performance regressions in the CI, it’s being used daily.
Dataroom sits at the heart of the deep learning lifecyle at Photoroom. From data ingestion, dataset curation then handling user feedback, to even making it possible to track performance regressions in the CI, it’s being used daily.
Backend architecture
In practice, Dataroom is a service layer sitting on top of an Elastic Search cluster, and object storage. It handles the API transparently, some validation tasks, background jobs and the web frontend. Both the service layer and the Elastic Search cluster can scale depending on the workload and amount of data. In addition to images, with corresponding segmentation masks and latent vectors, users can upload any kind of annotations and other metadata they want to associate with their images. All these attributes are indexed and for the images we compute and index vector embeddings, to make all the data searchable, both semantically and with attribute filters. Segmentation masks and image latents are not indexed, but they add a lot of flexibility for researchers to precompute and visualize different modalities at scale.
 The Dataroom architecture, in a nutshell
The Dataroom architecture, in a nutshell
Web UI
Together with this powerful backend, we’re open sourcing a user-friendly Web UI to make data exploration and curation more intuitive.
 The Dataroom web-frontend, here showing how images can be browsed, selected and tagged. On the right is the detail view of an image, also displaying the most similar images in the DB based on embedding vectors.
The Dataroom web-frontend, here showing how images can be browsed, selected and tagged. On the right is the detail view of an image, also displaying the most similar images in the DB based on embedding vectors. While the binary payloads cannot typically be part of a search (beyond a presence check), Dataroom makes it easy to visualize them.
While the binary payloads cannot typically be part of a search (beyond a presence check), Dataroom makes it easy to visualize them.
Datago - A fast client to bridge the gap with training needs
When a dataset has been curated, we would like to export it to a throughput-optimized format (like Parquet, MosaicStreamingDataset or Webdataset). At this stage, the data distribution is stable, and the raw speed of these formats for reading during training is beneficial.
At Photoroom, we quickly piled up lots tens of millions of images in Dataroom and were ready to train our next big vision model. We noticed however, that it would take around 2 weeks to just to export the training set. Exporting training sets is something we want to do often and quickly, so we decided to optimize this step.
There are typically two options: you can scale horizontally, or you can improve your stack vertically. The first option is more popular usually, but it incurs recurring costs, and it's not always faster to delivery as distributed data processing is often complex work on its own. Improving vertically first compounds, as you can combine it with horizontal scaling down the line. So, you guessed it, we optimized the stack vertically first. Some of this work was documented on X, but here's a summary of our requirements and solution.
Requirements
We need to query the DB for the samples we want to export, fetch everything then do the pre-processing. We want the payloads to be ready for training, which means that visual payloads need to be of the proper size, and typically distributed into a few aspect ratio buckets (we use Transformers, ViTs or DiTs let's say, and they require images which can be cut into patches).
Solution
After some detours where we tried writing better clients in Python and Go, we ended up using Rust, which seems to be the classic path these days to write performance critical code. We found that it has the following benefits over previous solutions:
Rust speed is state of the art, either from the standard crate (image now includes zune) or from off the shelf, safe crates (fast_image_resize).
First class python support from the rust ecosystem, thanks to Maturin
The package is statically built, so people in the team can “just grab the wheel" and not care about anything else. The user experience is not different from installing a pure Python package.
With datago we can move data from Dataroom into training compatible formats at GB/s speed per host. In practical terms we can export millions of images per day and per host.
 Exporting data at scale, ready for ML training jobs.
Exporting data at scale, ready for ML training jobs.
Dataroom in action
The ML team at Photoroom uses Dataroom daily. We're currently managing over 110 million base samples, which translates to over 1 billion attributes or payloads.
So far, Dataroom has been instrumental in:
Training our state-of-the-art segmentation model

Training our unique runtime steerable segmentation model (which responds to text and behavior hints)

Training multiple versions of the models that power our AI Backgrounds and Studio feature
Making it easier for the team to write code which is data-free and portable
model evaluations, low-bit model calibrations, non-regression tests
everything becomes simpler when curated datasets are available anywhere in a streaming fashion
Issues we faced along the way
Postgres is not the best fit
Initially, we used Postgres as the database for image metadata. At the time, our use-case was very simple: we only needed to retrieve images by source, so naturally, we added an index on this field. However, over time, we needed to filter on more and more combinations of fields. To make the queries performant we slowly added composite indices for almost every combination: source+aspect_ratio , source+width, source+short_edge, source+created_date, etc. Every index that was added, obviously slowed down the insertion of new records, which was an important metric for us as well. Eventually, we decided to store image metadata in OpenSearch instead. In addition to much better query performance, we also gained more advanced capabilities for querying vector embeddings.
OpenSearch mapping size
Dataroom allows end-users to attach any type of field as metadata on the image. The field is stored in OpenSearch as a field mapping. This is great, as it gives the ML team the flexibility to experiment and store any kind of data together with the image. Users loved this feature, in fact they loved it so much that they created 2000+ unique fields. They had no easy way of knowing what fields already exist in the data, therefore they would constantly create new ones accidentally, by misspelling or formatting the field name slightly differently.
This ballooned the OpenSearch mapping size and increased its memory footprint dramatically. Unfortunately OpenSearch started using a lot of memory as the mapping grows, and having 2000+ fields made that very painful.
After cleaning up the data, by consolidating similar fields and deleting unused ones, we decided to introduce a fixed schema. The user could from now on send data to pre-defined fields only. These fields can be configured in the django admin interface, so it’s still easy to add new ones, but we have more control now.
What's next? Try Dataroom
We're actively working on adding more features to Dataroom. A more powerful Dataset concept as well as a “views” feature to persist user queries are two important items on our roadmap that will land soon. We also have plans to improve the filtering capabilities of the web UI.
We hope it can help other deep learning teams tackle their data challenges more effectively.
The Dataroom team
Ales Kocjancic - Fullstack Web Developer, main author of Dataroom backend and web UI
Benjamin Lefaudeux - ML Lead, main author of datago, Dataroom contributor
Eliot Andres - CTO, Dataroom contributor, system architecture
Tarek Ayed - ML Data Engineer, Dataroom contributor and power user
Roman Frigg - ML Research Engineer, Dataroom and datago contributor


