One Rust core to power all Photoroom apps
In the first part of this series we discussed the overall technical strategy for sharing key features of the Photoroom apps, chief among them realtime-collaboration, across the three platforms, and introduced Crux, the tool we were fairly confident would help us get there. But we needed to prove it. In this post, we’ll take a closer look at our journey of gradually introducing it into the Photoroom Engine.
Inside the core
In the last post we introduced the basic interface which the core presents to the apps:
fn process_event(event: Event) -> Vec<EffectRequest>
fn handle_response<T>(effect: EffectRequest, response: T) -> Vec<EffectRequest>The Rust code inside the core does not implement this interface directly, there is a layer in between, provided by Crux, with a more ergonomic API.
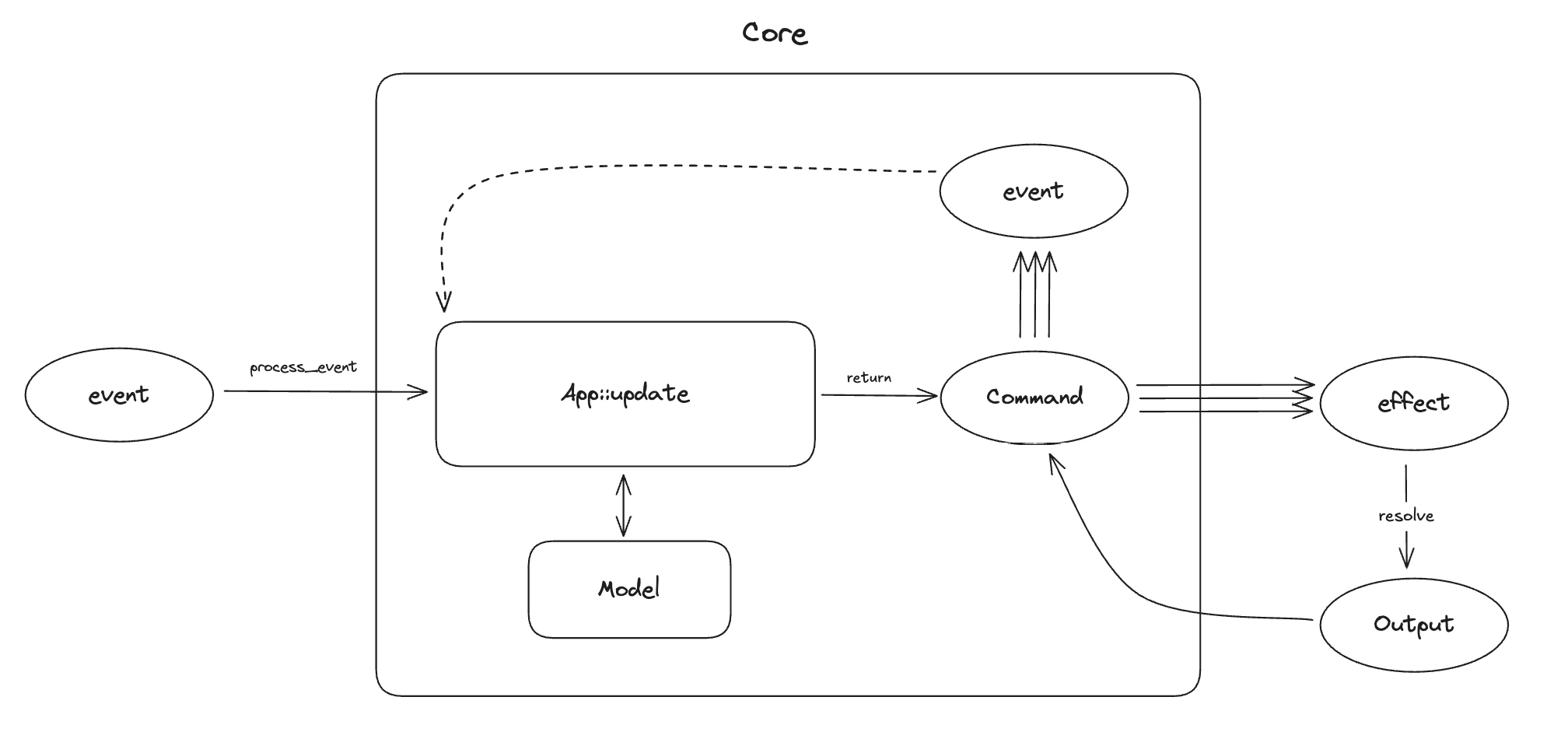
The inside of the core implements one key function:
fn update(event: Event, model: &mut Model) -> Command<Effect, Event>
In English: given an event, and some state, update can mutate the state, and return a Command.
Commands carry the “process” of interacting with the app. You can think of the native side of the app as having to sides – a driving side which is telling the core what to do, and the driven side which handles requests from the engine. Commands describe the process and logic of interacting with the driven side.
In that process, commands can emit effects (which get collected and returned as EffectRequest from the two functions above), and events, which get sent back to the update function, and act as a callback. Effect and Event, both enums, are types defined by the core - Effect covers the possible types of I/O the core will request, and Event covers all the possible actions the core can handle.
Commands typically get built by capabilities - platform agnostic interfaces for a kind of I/O. For example, Crux comes with an HTTP client, crux_http.
 An example
An example
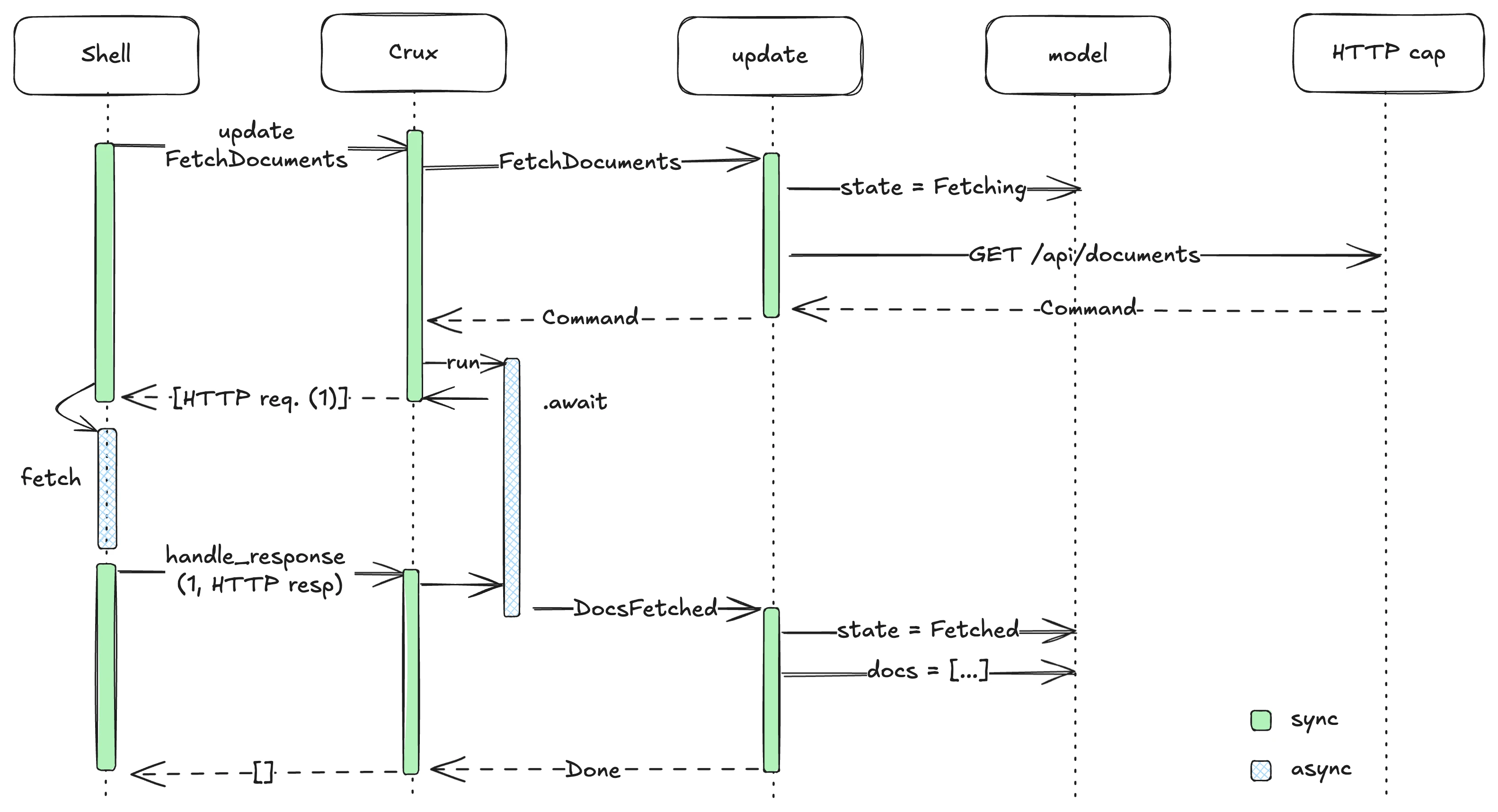
A simple interaction like fetching a page from the documents API might unfold like this:
A user opens the page
As a result, a
FetchDocumentsevent is passed toprocess_eventupdateis called withFetchDocumentsand changes themodelto a state showing that documents are loading, so that the UI can observe this and show a loading state. It uses the HTTP capability to start a request to the right API endpoint and registersDocumentsFetchedas the callback event. The created command is returned from theupdatefunction.Crux runs the command and the first thing the command does is request a HTTP request to the API.
process_eventreturns this request back to the app, which starts it (for example, on iOS, it will useURLRequestto do that).The HTTP request completes, and the app calls
handle_responsewith it.The result makes it back to the command, which wraps it in the
DocumentsFetchedevent which it sends.updateis called again, this time withDocumentsFetched, and loads the received documents into the state, and updates it to indicate loading has finished. Nothing else needs to happen, soupdatereturns aCommand::done()- a no-op.handle_responsereturns an empty list
Here is the same thing in a picture:
 One thing we completely skipped is the UI updates. That’s partly because we’ll dedicate a whole post in this series to how our approach to updating the UI has evolved over the last year or so.
One thing we completely skipped is the UI updates. That’s partly because we’ll dedicate a whole post in this series to how our approach to updating the UI has evolved over the last year or so.
But the basic idea is the same - in the core, next to update there is another function:
fn view(model: &Model) -> ViewModelIt’s job is to convert the internal state of the core into a type that represents what should be shown by the UI.
Both update and view can be thought of as pure functions – synchronous and without I/O, although not quite pure due to the stateful model – and the entire domain is captured in data types, defined by the Event, Effect, Model and ViewModel types. This makes the core logic very easy to test, and we’ll talk about that in a separate post later in this series as well.
Introducing Crux into the Photoroom engine
To prove that this architecture will work for Photoroom, we needed to pick a small, isolated feature to trial it with. We quickly identified the perfect candidate on the upcoming features list: comments on projects.
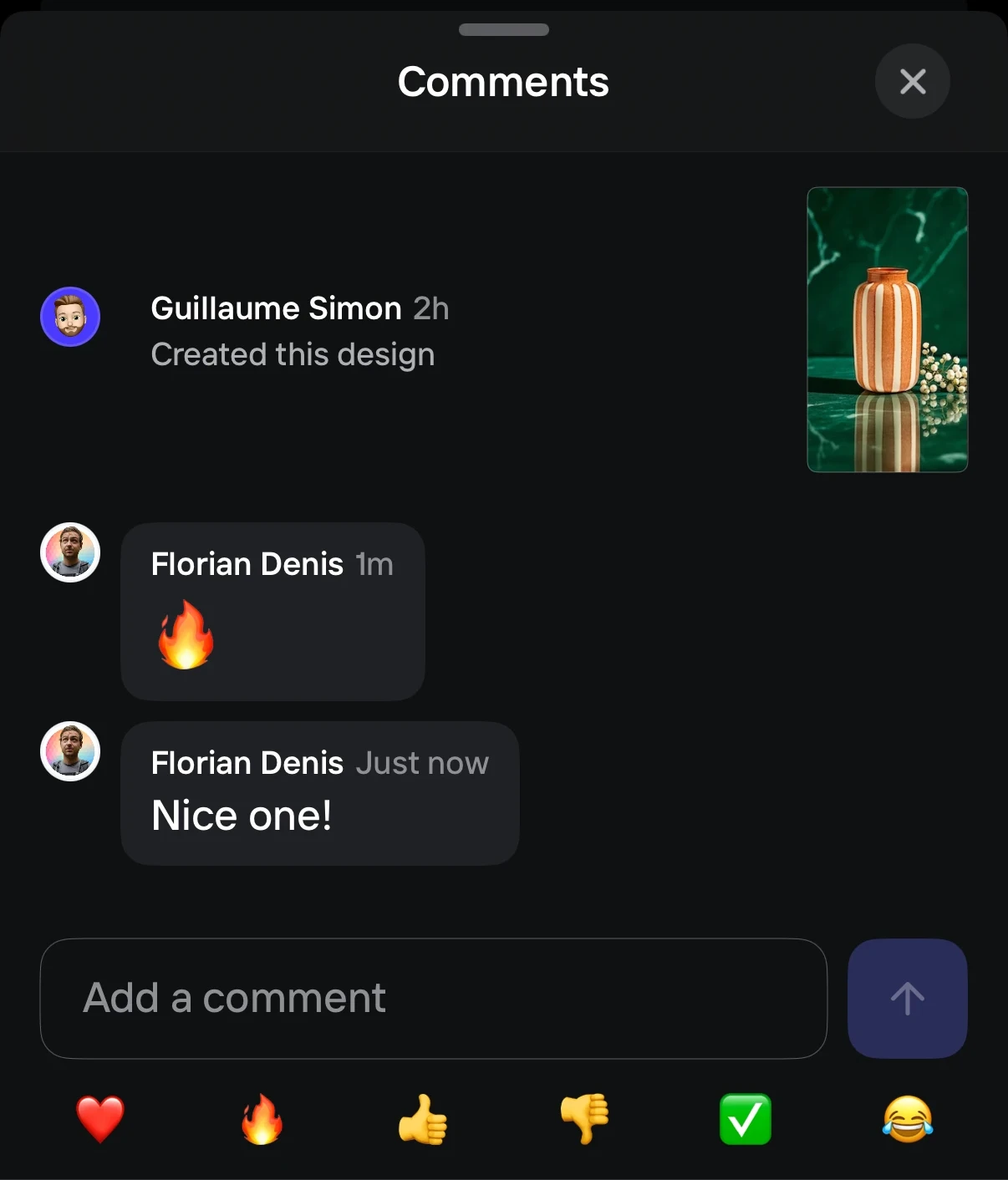
It’s a reasonably simple feature, it only needs HTTP support, and at the same time, implementing a good UX with loading indication and optimistic updates is not completely trivial and would give us a good sense of what Crux is like in practice.
To implement comments in the engine, we needed to solve four problems:
Integrate a Crux app into the existing Photorom engine foreign-function interface (FFI)
Implement the crux_http support for the existing platforms
Build the logic of interacting with the comment API
Build the UI using these new features of the engine
Foreign function interface
The FFI is what allows Swift and Kotlin to call the engine’s native Rust and C code directly. The interface closely resembles the example with two functions at the top of this post, and the data sent back and forth is serialized and exchanged across the boundary as byte buffers.
In stock Crux apps, the FFI interface, which allows Rust functions to be exposed to Swift and Kotlin or from WebAssembly to JavaScript in the browser is provided by UniFFI, and developers rarely need to look at it. However, the Photoroom engine is not pure Rust. Some of the components are using C libraries, and so the engine’s FFI is hand-written and uses C calling conventions. The other difference to stock Crux is that Crux uses bincode serialization by default. We wanted to use JSON instead, both for human readability, making debugging easier, and for the built-in support in the browser and in Swift and Kotlin.
We knew implementing the FFI was going to be quite a low-level job, but fortunately the API is not very large, and once it was integrated we didn’t really need to touch it again. It ultimately only took about a day to make it work.
The first step was to expose the crux core calls as C functions in the engine:
#[no_mangle]
pub unsafe extern "C" fn pg_process_event(
event: *const u8,
size: usize,
out_size: *mut usize,
) -> *const u8 {
let bytes: &[u8] = unsafe { std::slice::from_raw_parts(event, size) };
let mut event_deserializer = deserialize_from_slice(bytes);
let mut effects_bytes = vec![];
let mut effects_serializer = serialize_into_vec(&mut effects_bytes);
CORE.process_event(&mut event_deserializer, &mut effects_serializer);
out_size.write(effects_bytes.len());
let effect_ptr = effects_bytes.as_ptr();
std::mem::forget(effects_bytes);
effect_ptr
}
#[no_mangle]
pub unsafe extern "C" fn pg_handle_response(
effect_id: u32,
response: *const u8,
size: usize,
out_size: *mut usize,
) -> *const u8 {
let response_bytes: &[u8] = unsafe { std::slice::from_raw_parts(response, size) };
let mut response_deserializer = deserialize_from_slice(response_bytes);
let mut requests_bytes = vec![];
let mut requests_serializer = serialize_into_vec(&mut requests_bytes);
CORE.handle_response(
effect_id,
&mut response_deserializer,
&mut requests_serializer,
);
out_size.write(requests_bytes.len());
let effect_ptr = requests_bytes.as_ptr();
std::mem::forget(requests_bytes);
effect_ptr
}This may look a little bit scary at first, but all we’re doing here is converting unsafe raw pointers into Rust slices, passing them to the core API and then converting the result back to a byte pointer. We also need to tell the caller how many bytes to expect in the output.
The core takes the input and provides the output as serde (de)serializers, so we can easily change the data format we’re exchanging over the boundary (and we did later switch to MessagePack without complications).
On the app side, the code is almost a mirror image, but in a different language. Here is the Swift version for example:
final class Bridge: Sendable {
func processEvent(event: Event) throws -> [Request] {
var requestsSize: UInt = 0
let requestsPtr = try withEncodedBuffer(event) { eventPtr, eventSize in
pg_process_event(eventPtr, eventSize, &requestsSize)
}
guard let requestsPtr else {
throw BridgeError.engineReturnedNullPointer(method: "pg_process_event")
}
return try Managed<[Request]>(requestsPtr, requestsSize).value()
}
func handleResponse<R: Encodable>(id: UInt32, response: R) throws -> [Request] {
var requestsSize = UInt()
let requestsPtr = try withEncodedBuffer(response) { responsePtr, responseSize in
pg_handle_response(id, responsePtr, responseSize, &requestsSize)
}
guard let requestsPtr else {
throw BridgeError.engineReturnedNullPointer(method: "pg_handle_response")
}
return try Managed<[Request]>(requestsPtr, requestsSize).value()
}
}That’s the basic FFI done, we now have a bridge over which the app and the core can exchange messages.
The next step was crux_http support. Launching on the web first, doing this in TypeScript was trivial, especially compared to the FFI. The capability implementation for HTTP is just a thin wrapper around fetch:
export class Http {
async fetch(request: HttpRequest): Promise<HttpResult> {
try {
const headers: Array<[string, string]> = request.headers.map((header) => [header.name, header.value]);
const fetchResponse = await fetch(request.url, {
method: request.method,
headers,
body: request.body.length > 0 ? request.body : undefined,
});
const body = new Uint8Array(await fetchResponse.arrayBuffer());
const httpResponse = {
status: fetchResponse.status,
headers: Array.from(fetchResponse.headers.entries()).map(
([name, value]): HttpHeader => ({
name,
value,
})
),
body,
};
return { Ok: httpResponse };
} catch (error: any) {
return { Err: { Io: error.toString() } };
}
}
}
This fetch method is called whenever the core returns a request for an effect of type Http (as opposed to, say, Time).
The Photoroom engine already had an established set of foreign language bindings, including TypeScript, and all this additional code slotted right in and could present a nice TypeScript API to the app. The web app uses MobX for state management, which was a great fit to expose the core’s view model to the React UI.
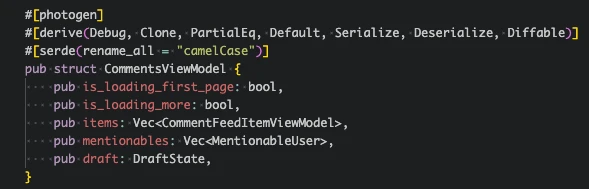
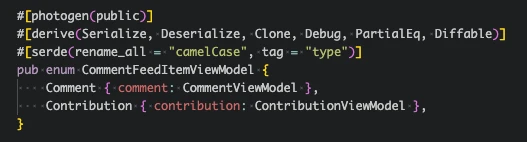
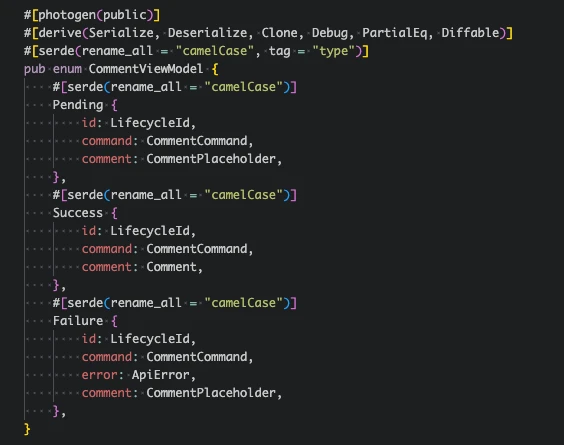 For the comments, the view model is quite simple, it exposes some global loading state – the items loaded in the comment feed, users who can be at mentioned in new comments, and draft comment state used to show the comment which the user is currently composing. The MobX store holding this view model has methods such as
For the comments, the view model is quite simple, it exposes some global loading state – the items loaded in the comment feed, users who can be at mentioned in new comments, and draft comment state used to show the comment which the user is currently composing. The MobX store holding this view model has methods such as createComment and editComment to interact with the comments, which send events to the core.
The React UI never needs to worry about making HTTP requests, paginating through the comments or error handling. All of that is done in the engine and the view model always contains the relevant up to date information to show in the UI. Since the MobX store is observable, the relevant React components re-render whenever the state in the engine changes. The same is true about the Swift UI and Jetpack Compose counterparts. And all that network loading and error handling logic could be reused across the three apps.
Type generation with Typeshare
In the example above you may have noticed references to types like HttpRequest. These are defined by crux_http as a protocol to exchange data between the core and the app. The TypeScript types in the web app match one to one with the original Rust types.
This is the beauty of the event-based model we chose: with it's simple interface, it transforms an exposing-FFI problem to type-generating problem; What that means in practice is that in order to deliver the best developer experience possible, we need to invest into type generation.
Crux has a built in support for generating types from Rust to TypeScript, Kotlin and Swift, but it has some limitations, and only supports the default bincode serialization. It works fine for smaller Crux apps, but was not going to work for our engine.
Initially, we wrote these types by hand, but we knew it wouldn’t take long before we needed to automate this to make the process less tedious and error prone. We looked for alternatives and found 1password’s Typeshare, which worked better for our needs. Unfortunately it had a few shortcomings that made it hard to work with our existing data-model. So we forked it and extended it to support those.
Amongst the changes that we made, a lot were made to accommodate the way we tend to write Swift, Kotlin and Typescript code - so that those generated types would feel “idiomatic” for any Photoroom app developer. But a few of the major features we added are worth mentioning here:
Supporting all serde enum types.
serde can generate JSON representation of algebraic enums following 3 different conventions. If you have a Rust enum
enum MyEnum {
VariantA(MyNestedTypeA)
}it can get serialized as:
An “Externally tagged” enum (the
serdedefault), representing the associated values as a sub-object that is keyed by the variant:{ "VariantA" : { /* Fields of 'MyNestedTypeA' */ } }An “Internally tagged” enum (
#[serde(tag = "name")]), where the type and fields of the associated value are inlined in the same object.{ "name": "VariantA", /* Fields of 'MyNestedTypeA' */ }An “Adjacently tagged” enum (
#[serde(tag = "name", content = "attributes")], the only thing Typeshare supports), representing the variant as an object with 2 keys (type and content):{ "name": "VariantA", "attributes": { /* Fields of 'MyNestedTypeA' */ } }
Allowing Typeshare to support all 3 kinds of enums was one of the major decision that led us to rollout our own fork, since our data model was already massively using the “internally tagged” representation that Typeshare didn’t naturally support.
Have the Kotlin code generation be able to generate Moshi adapters
Moshi is a major JSON serialization library, widely used in the Android ecosystem, and our Android app was already using it. It only made sense for us to also use it in the Photoroom engine. Unfortunately, Typeshare’s choice for Kotlin code generation is to target the kotlinx.serialization library.
As such, we made heavy modification to the Koltin code generation so that it would generate Moshi adapters instead of KotlinX serializers.
Make the Swift, Kotlin and Typescript type representation be a strict representation of the Rust type representation
…in order to represent anonymous structs. If you have the following Rust enum
enum MyEnum {
VariantA { my_nested_field_1: String, my_nested_field_2: MyNestedStruct }
}Typeshare would create a MyEnumVariantAInner type to represent the anonymous struct here, and use it as the associate value of VariantA. For example, in Swift:
struct MyEnumVariantAInner {
let my_nested_field_1: String
let my_nested_field_2: MyNestedStruct
}
enum MyEnum {
case variantA(MyEnumVariantAInner)
}
Since our goal as Engine developers is to ensure the best developer-experience possible for our app developers, we thought that it was important that the Swift, Kotlin and Typescript types to strictly replicate the Rust ones: if you see a type in our generated code, then you must find a type with the same name in the Rust code and be able to modify it to suit your needs.
As such, we also made modifications to all the languages to support inlining of anonymous struct, e.g in Swift:
enum MyEnum {
case variantA(my_nested_field_1: String, my_nested_field_2: MyNestedStruct)
}
Other quality-of-life improvements
Amongst other things, we also made it possible to generate branded type-aliases (so that an app developer would not accidentally pass a CommentId in an event expecting a ProjectId, even though there are both type-aliases to Uuid).
But above all else, one of the big features the custom type generation allowed us to implement was more efficient transfer of view model updates from the engine to the bindings. The evolution of our approach to updating the view model deserves its own post, and we will cover it in the next part of this series. If this sort of work sounds exciting to you, we’re hiring a head of cross-platform to provide a seamless experience to millions of users. Learn more here.


