 Early steps in the model training
Early steps in the model training
We’re training a text-to-image model from scratch and are publishing the code, weights, and research process in the open. The goal is to build something both lightweight and capable: easy to train and fine-tune, but still making use of the latest advances in the field.
We’ll publish the model weights (Hugging Face, diffusers-compatible) under a permissive license, together with other useful resources. More than just weights, we want the process itself to be transparent and reusable: how we trained, what worked, what didn’t, and the little details that usually stay hidden.
To that end, we’ll be documenting the journey through blog posts, intermediate releases, and eventually a full ablation study. Our hope is that this becomes not just a strong open model, but also a practical resource for anyone interested in training text-to-image models from scratch.
What we’ve done so far
Here’s a sneak peek of where we are right now and we’ll leave further technical training details for our next blog post.
For the past few weeks, we’ve been experimenting with a wide range of recent techniques to refine our training recipe:
On the architecture side, we tested DiT [1], UViT [2], MMDiT [3], DiT-Air [4], and our own MMDiT-like variant which we call Mirage.
For losses, we tried REPA [5] with both DINOv2 [6] and DINOv3 [6] features and contrastive flow matching [7].
We also integrated different VAEs, including Flux’s [8] and DC-AE [9], and explored recent text embedders such as GemmaT5 [10].
In addition, we looked at a few other techniques like Uniform ROPE [11], Immiscible [12], distillation with LADD [13], and the Muon optimizer [14].
Finally, we paid close attention to the training process itself, carefully exploring hyperparameters and implementation details such as EMA and numerical precision.
We believe we already have something very exciting in our hands and we’re really eager to show you. Here are some early samples from our best checkpoint so far.
|
|
|
|
|
|






These images come from a 1.2B-parameter Mirage model, trained for 1.4M steps at 256-pixel resolution for less than 9 days on 64 H200s. This checkpoint in particular uses REPA with DINOv2 features, Flux’s VAE, and GemmaT5 as our text embedder. Finally, we distilled it with LADD so it can generate in 4 steps. Below are animations built from every checkpoint, using the same prompt and seed, so you can see the model’s progression from scratch to the final result.
|
|
|
|


The plot below shows how training went for this model. We started with REPA (blue), which helped the model converge faster. Disabling it later in training (orange) led to a further drop in the validation loss (we’re currently running more experiments to better understand REPA’s impact, but it seems switching it off after convergence helps fine-tune the loss). Finally, we added exponential moving average (green), which we integrated in the codebase at that stage of training and saw a positive impact.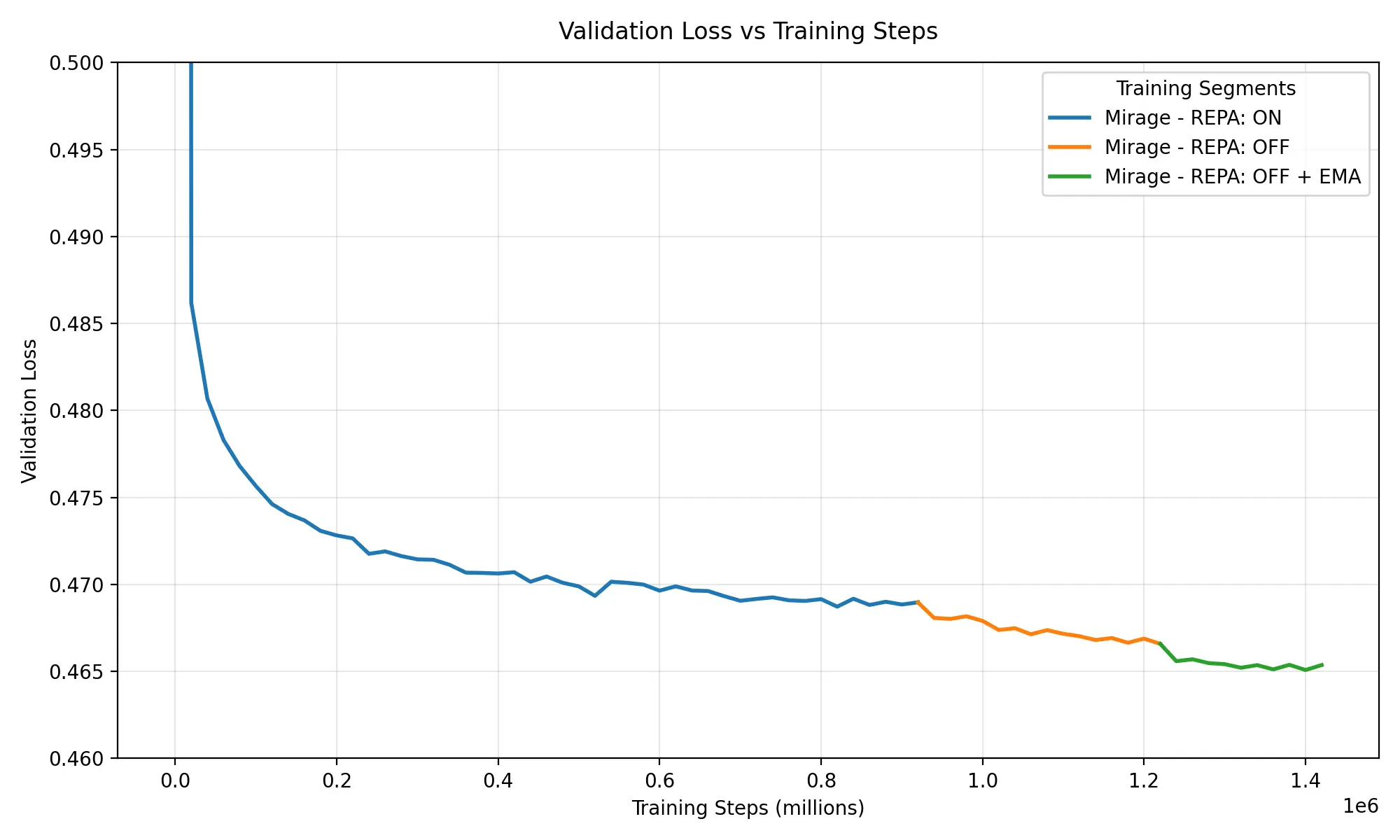
We'll talk more about this and other experiments in our next blog post, which will come with the first model release.
What’s next?
This wraps up the first of a series of research blog posts and releases we’re planning. There’s still plenty in the pipeline:
We’ve just launched training at 512-pixel resolution with both Flux’s VAE [8] and DC-AE [9] and distillation for all our 256-pixel resolution models.
We’ve started exploring preference alignment, currently looking at supervised finetuning and DPO [15] and ready to launch a training.
We’re sketching out the roadmap of upcoming experiments and considering other recent techniques.
In parallel, we’re preparing the first release in Diffusers and Hugging Face (coming shortly), while documenting everything along the way for the ablation study.
Stay tuned for the next blog post, which will include the first model release and the details of how we trained it.
Interested in contributing?
We’ve set up a Discord server (join here!) for more regular updates and discussion with the community. Join us there if you’d like to follow progress more closely or talk through details.
If you’re interested in contributing, you can either message us on Discord or email [email protected]. We’d be glad to have more people involved.
The team
This project is the result of contributions from across the team in engineering, data, and research: David Bertoin, Quentin Desreumaux, Roman Frigg, Simona Maggio, Lucas Gestin, Marco Forte, David Briand, Thomas Bordier, Matthieu Toulemont, Benjamin Lefaudeux, and Jon Almazán. We’re hiring for senior roles!
References
[1] Peebles et al. Scalable Diffusion Models with Transformers
[2] Bao et al. All are Worth Words: A ViT Backbone for Diffusion Models
[3] Esser et al. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
[4] Chen et a. DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
[5] Yu et al. Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
[6] Oquab et al. DINOv2: Learning Robust Visual Features without Supervision
[7] Siméoni et al. DINOv3
[8] Black Forest Labs, FLUX
[9] Chen et al. Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
[10] Dua et al., EmbeddingGemma
[11] Jerry Xiong On N-dimensional Rotary Positional Embeddings
[12] Li et al. Immiscible Diffusion: Accelerating Diffusion Training with Noise Assignment
[13] Sauer et al. Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
[14] Jordan et al. Muon: An optimizer for hidden layers in neural networks
[15] Rafailov et al. Direct Preference Optimization: Your Language Model is Secretly a Reward Model

