Skip to content
Product
Solutions
Resources
Enterprise
Pricing
Log in
Contact sales
Start creating
Home
Inside Photoroom
Inside Photoroom
Go behind the scenes with the team building the future of AI photo editing.
Product updates
Newsroom
Stories from the team
Data insights
Meet the new Photoroom: People don't buy products, they buy pictures
Matthieu Rouif
Product updates
See all
What's new in product: May 2026
Jeanette Sha
What's new in product: April 2026
Jeanette Sha
What's new in product: March 2026
Jeanette Sha
What's new in product: February 2026
Jeanette Sha
What's new in product: January 2026
Shelley Burton
What's new in product: December 2025
Shelley Burton
See all
Newsroom
Pay only for what passes: Photoroom launches the first contractual AI visual guarantee
Lianne Hunter
Built in, not bolted on: Photoroom inside Capture One 16.8
Jeff Strauss
State of GenAI in Marketplaces 2026: Key insights from industry leaders
Aisha Owolabi
Photoroom featured on This Week in Startups: Our journey to 300M users
Aisha Owolabi
Introducing Studio HD: Our most realistic AI Backgrounds model yet
Aisha Owolabi
Photoroom acquires GenerateBanners and launches Visual Ads Automation—first-to-market GenAI engine for large-scale ad creatives
Lyline Lim
Why sustainable AI Is a win-win-win: Photoroom’s path to greener, faster, smarter AI
Lyline Lim
Photoroom launches 3 new AI tools for product photography
Aisha Owolabi
See all
Stories from the team
See all
Senior Claude Reviewer Is Not a Good Use of Engineering Talent
Marek Zaremba-Pike
The Laptop Is the Wrong Place to Run Coding Agents
Marek Zaremba-Pike
Building a multi-provider inference backend
Paul Berthaux
Optimizing our inference backend with custom load balancing
Paul Berthaux
AI coding guardrails are mostly the old guardrails
Marek Zaremba-Pike
What I learned from vibecrafting my first physical product
Matthieu Rouif
See all
Data insights
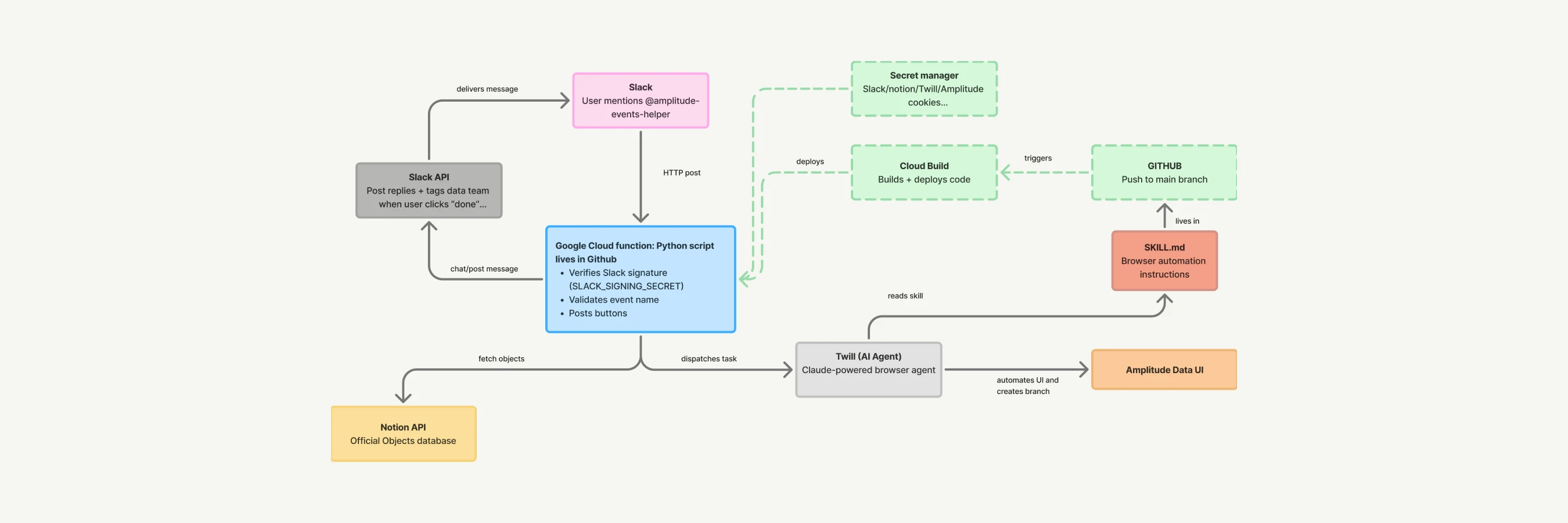
How we automated Amplitude event governance with a Slack bot and AI
Charlotte de Thiersant
Never underestimate the power of exposure events — in the context of sequential testing
Charlotte de Thiersant
Understanding feature flags: The foundation of reliable A/B tests
Charlotte de Thiersant
Why sequential testing is the right way to experiment at the speed of PLG apps like Photoroom
Charlotte de Thiersant
See all
Start selling at first sight
Get listing-ready product visuals in seconds.
Start free trial
Contact sales