We benchmarked four leading AI image-editing models across 4,250 virtual-model generations. The strongest base model preserved full product fidelity in only 29.0% of cases. Applying Photoroom’s Fidelity Layer raised the pass rate to 38.2%.
There has been a lot of progress in image-editing models recently. Labs like Google and OpenAI have released frontier models that are a real step up in quality. Realism is much better, obvious visual glitches are far less common, and these models can now natively edit images: you provide an image and a prompt, and the model transforms it.
That has unlocked a lot of new use cases. For e‑commerce, one of the most exciting is turning a flat-lay product shot into a lifestyle image of a virtual model wearing it. At Photoroom we call this virtual model.
But for e‑commerce, one thing is critical: product fidelity. The product in the generated image has to look exactly like the real one—every button, zipper, logo, stitch and color. Professional brands cannot advertise products with images that do not accurately depict the real thing.
 Left: input image. Right: generated image. Center: zoom on the collar, where the plain red band is transformed into a rainbow stripe.
Left: input image. Right: generated image. Center: zoom on the collar, where the plain red band is transformed into a rainbow stripe.
At Photoroom, we have been building applications on top of the latest frontier models, with a strong focus on e‑commerce. We know how much fidelity matters to brands and where these models tend to break.
To move from intuition to numbers, we benchmarked the leading image-editing models on product fidelity. We then tested whether Photoroom’s Fidelity Layer—a reasoning-based correction system that detects and fixes fidelity issues—could improve the strongest base-model result.
The Photoroom Product Fidelity Benchmark
Models
We evaluated four models, all at 2K resolution and using the same prompt:
Nano Banana 2: Google's latest editing model.
Nano Banana Pro: Google's most capable editing model.
GPT Image 2 Medium: OpenAI's latest image-editing model.
FLUX.2 Klein 9B: one of the strongest open-weights image-editing models, from Black Forest Labs.
Methodology at a glance
850 products across clothing, footwear, bags, jewelry and accessories
Each product run through all four models at 2K resolution using the same prompt
10 trained annotators; every generation reviewed by at least 3
Custom side-by-side UI, independent pan/zoom, 30-second minimum review time
One flag = fail: a generation passes only if no annotator flags an issue
Why one flag equals fail
The obvious alternative is majority pass: a generation is fine if at least 2 of 3 raters say so. We considered it and we tested it. It is the wrong call for product fidelity.
We sampled cases where one rater flagged an issue the other two had missed, and reviewed them manually. The lone flagger was usually right: the other two had not zoomed in enough, or the issue was subtle.
Product fidelity annotation is recall-limited, meaning humans miss issues, they do not invent them.
It also matches what a buyer actually cares about: if one careful pair of eyes spots a problem, the product on the shelf has a problem.
Results
We first evaluated the four base models out of the box. We then evaluated Nano Banana 2 with Photoroom’s Fidelity Layer applied on top, using the same fidelity benchmark.
The leaderboard below shows both the base-model results and the improvement produced by the correction layer.
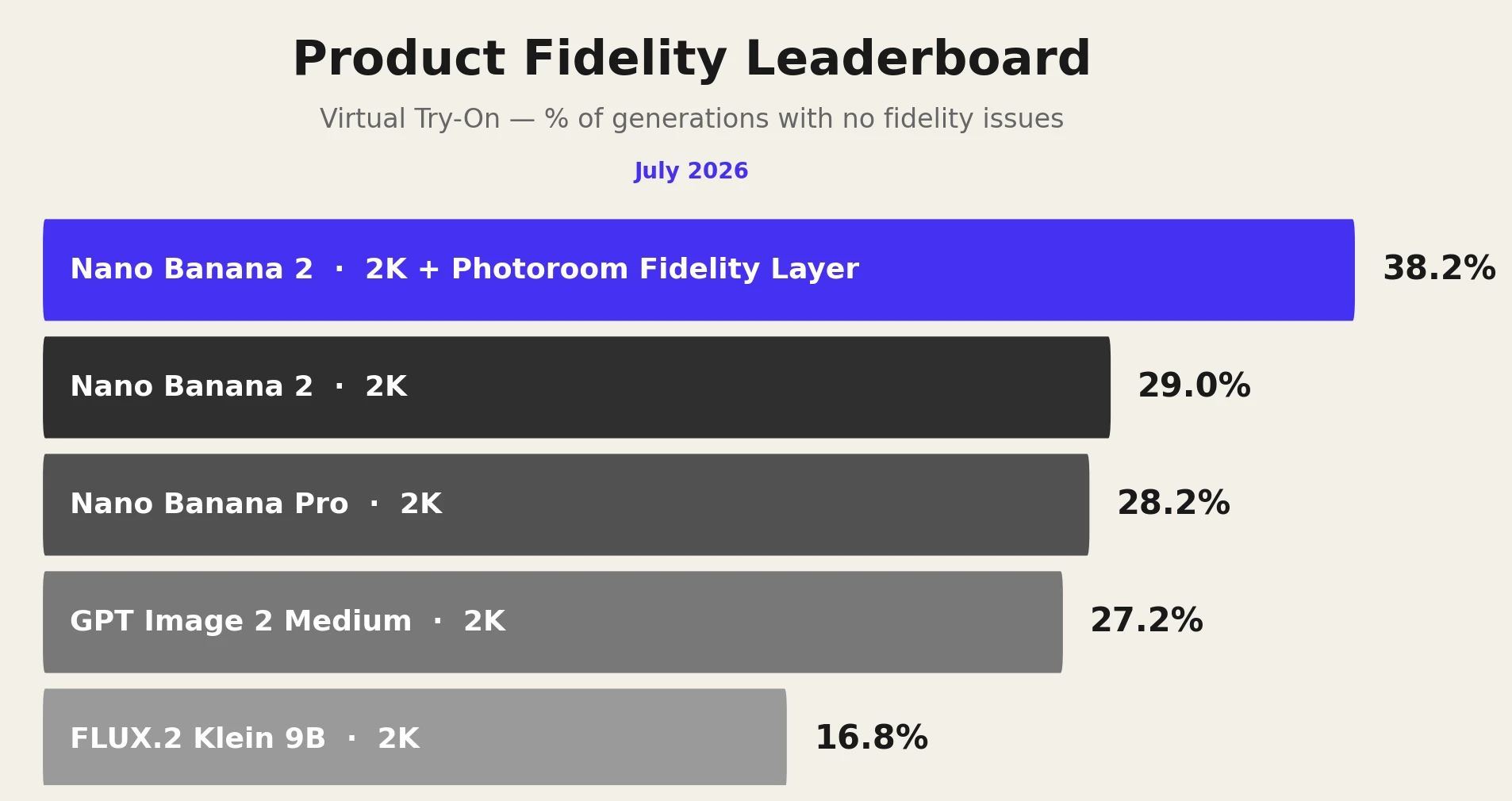 Product Fidelity Leaderboard, July 2026. Four image-editing models evaluated out of the box, plus Nano Banana 2 with Photoroom’s Fidelity Layer applied as a correction system.
Product Fidelity Leaderboard, July 2026. Four image-editing models evaluated out of the box, plus Nano Banana 2 with Photoroom’s Fidelity Layer applied as a correction system.
Results at a glance
The complete results are also reproduced below in text:
Model | Provider | Pass rate (no fidelity issues) |
Nano Banana 2 + Photoroom Fidelity Layer | Google + Photoroom | 38.2% |
Nano Banana 2 | 29.0% | |
Nano Banana Pro | 28.2% | |
GPT Image 2 Medium | OpenAI | 27.2% |
FLUX.2 Klein 9B | Black Forest Labs | 16.8% |
Base models remain far from solving product fidelity
Looking first at the base models, none is close to solving the task.
Nano Banana 2 achieves the highest pass rate at 29.0%, followed closely by Nano Banana Pro at 28.2% and GPT Image 2 Medium at 27.2%.
The differences between those three models are small. Depending on the products included in the benchmark, any of them could come out on top. Choosing between them should therefore also take into account cost, latency and how well each model fits a particular workflow.
The more important result is that even the strongest model passes fewer than one in three product-fidelity checks.
FLUX.2 Klein 9B ranks below the three frontier models, with a 16.8% pass rate. Around 28% of its outputs are invalid virtual-model generations: the garment may be left floating, the model may have serious anatomy artifacts, or the product may disappear entirely. For the other three base models, that rate is between 4% and 8%.
The Photoroom Fidelity Layer improves the strongest result
The narrow gap between the three frontier models suggests that choosing a slightly better base model alone will not solve the problem.
The Photoroom Fidelity Layer is a correction system designed to sit on top of an image-editing model. It compares the generated image with the original product, reasons through any fidelity issues, localizes the problematic areas, and uses that analysis to guide a corrected generation.
 Product reference, Nano Banana 2 output, and the result with Photoroom’s Fidelity Layer. The base model distorts the brand's logo, while the Fidelity Layer preserves the text and surrounding details more faithfully.
Product reference, Nano Banana 2 output, and the result with Photoroom’s Fidelity Layer. The base model distorts the brand's logo, while the Fidelity Layer preserves the text and surrounding details more faithfully.
Applied to Nano Banana 2, the Fidelity Layer raises the pass rate from 29.0% to 38.2%, a relative improvement of roughly one third.
This does not mean that product fidelity is solved. A 38.2% pass rate still leaves substantial room for improvement. But it shows that a system built around the generation model can meaningfully outperform using the base model alone.
Where the failures happen
We grouped the annotators’ explanations into failure categories across the four base models. The dominant failure modes are:
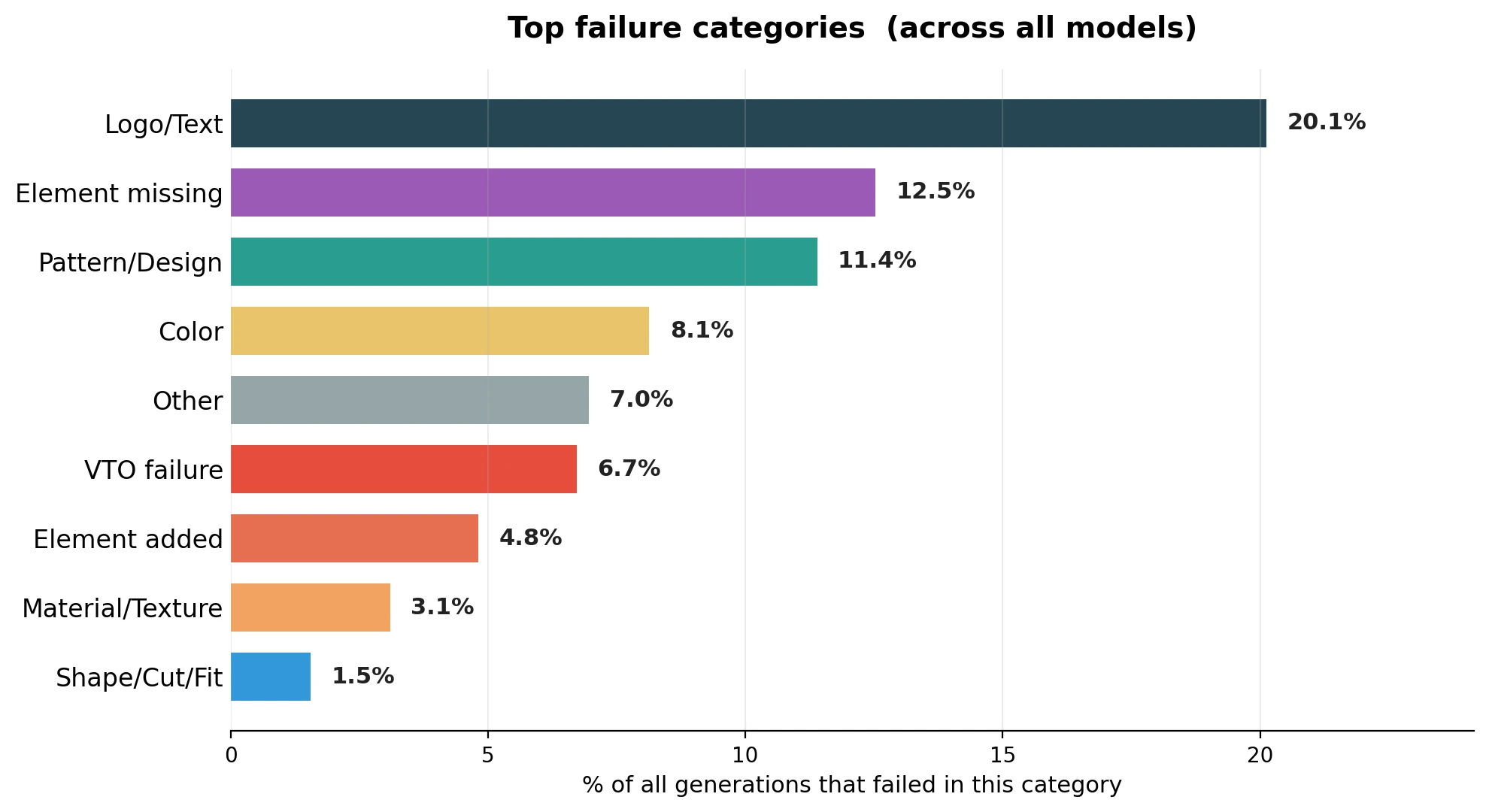 Breakdown of product-fidelity failures across all four base models. Percentages represent the share of all generations affected by each category.
Breakdown of product-fidelity failures across all four base models. Percentages represent the share of all generations affected by each category.
Logo and text distortion was the most common failure, affecting 20.1% of all base-model generations. It was followed by missing or changed elements, pattern and design changes, color shifts, and invalid virtual-model generations.
Here are some more examples of failure cases:
 Top left: color shift on the backpack. Top right: flower detail missing. Bottom left: text on the t-shirt back has changed. Bottom right: extra button added on the blazer.
Top left: color shift on the backpack. Top right: flower detail missing. Bottom left: text on the t-shirt back has changed. Bottom right: extra button added on the blazer.
What to do about it
The benchmark points to two complementary needs: automatically correcting fidelity issues during generation, and giving users precise control over the cases that still require manual intervention.
The Photoroom Fidelity Layer addresses the first. For hands-on corrections, Brush Fixer lets users paint over a specific problem area—a distorted logo, a missing button or an incorrect detail—and regenerate only that region using the original product as reference.
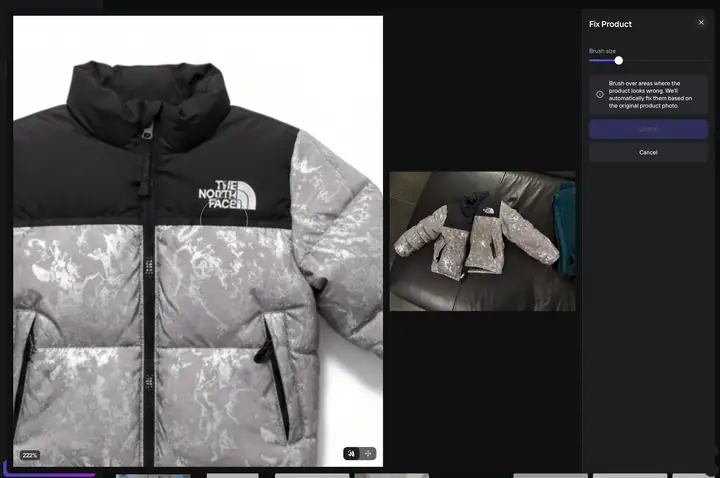 Brush Fixer in action: brush over the distorted text, regenerate only that region against the reference product.
Brush Fixer in action: brush over the distorted text, regenerate only that region against the reference product.
What's next
Benchmarking product fidelity is an important step toward improving it, but fidelity is not the only dimension that matters to brands.
Realism, photographic integrity, adherence to brand guidelines and consistency across an entire catalog are also important, and they involve real trade-offs. We will continue measuring and publishing what we learn across these dimensions.
The Fidelity Layer and Brush Fixer are part of a broader set of tools and in-house image-editing models we are building to help e‑commerce brands generate product imagery that meets a professional quality bar.


















